


À l’instar de nombreuses autres organisations, les bibliothèques doivent impérativement communiquer pour être pérennes. L’enjeu, pour ces dernières, est de communiquer efficacement à propos de leurs services, programmations, ressources, activités et missions, et, in fine, susciter de l’engagement1 auprès des publics qu’elles touchent. Parmi les supports communicationnels les plus utilisés par les bibliothèques pour répondre à cet enjeu, on peut compter les affiches, les magazines et les programmes imprimés. Cependant, depuis le début des années 1960 le développement du numérique provoque des changements au sein des bibliothèques (Chevry, Pébayle et Slouma, 2016). Elles ont ainsi connu tour à tour le site Internet qui permet la diffusion d’informations auprès d’une audience à la fois nombreuse et distante, et le Web social qui autorise plus d’interactions avec cette même audience.
Toutefois, les sites Internet institutionnels, qui étaient jusque-là considérés comme le principal mode d’accès à distance aux services et aux informations des bibliothèques, voient leur pertinence remise en cause tant les usagers ne semblent plus aujourd’hui s’y intéresser. Par conséquent, ils ne peuvent plus garantir la communication entre les bibliothèques et les usagers (Kouakou, 2014). Les réseaux sociaux numériques (RSN) sont désormais les plateformes les plus fréquentées et les plus utilisées par les internautes (Kouakou, 2014). Il est d’ailleurs aussi démontré que les usagers sont plus intéressés par les informations diffusées sur ces médias plutôt qu’aucun autre (Izuagbe et al., 2019). Au vu de ces éléments, la présence des bibliothèques sur les réseaux sociaux numériques se révèle être d’autant plus importante et nécessaire. Les bibliothèques ont donc dû repenser leur stratégie communicationnelle en ligne et aller chercher les usagers là où ils se trouvent pour maintenir le contact avec eux, poursuivre leurs missions et valoriser leurs services. On observe donc depuis une dizaine d’années que l’usage des outils de réseaux sociaux numériques tend à se développer chez les bibliothèques pour multiplier et améliorer les échanges et les interactions avec les publics (Audouard, 2018 ; Gaillard, 2018 ; Georges, 2010 ; Kouakou, 2015). Ces dispositifs sont finalement devenus centraux dans la stratégie communicationnelle en ligne des bibliothèques (Harrison et al., 2017).
Les réseaux sociaux numériques permettent d’envisager de nombreuses possibilités et de nouvelles façons de valoriser les collections et les services, de toucher de nouveaux publics, de créer du lien social, d’impliquer les lecteurs dans la documentarisation ou la collecte de documents numériques, de partager toutes sortes d’informations (Al-Daihani et Abrahams, 2016 ; Georges, 2010 ; Harrison et al., 2017 ; Kouakou, 2014, 2015 ; Slouma et Chevry Pébayle, 2017). Les bibliothèques souhaitent instaurer à l’aide de ces dispositifs « une meilleure relation entre institutions et usagers » (Chevry Pébayle et Rondot, 2018, p. 81). « Ainsi se dessine, derrière l’utilisation croissante des RSN, l’existence d’une congruence (Candel, 2007) entre fonctionnalités supposées d’un dispositif technique et objectifs communicationnels et médiationnels d’une institution culturelle. » (Chevry Pébayle et Rondot, 2018, p. 81-82).
Dans une de nos recherches en cours, nous nous intéressons à l’usage que font les bibliothèques municipales françaises de la plateforme Twitter qui est, avec Facebook, l’un des réseaux sociaux numériques les plus utilisés par les bibliothèques pour leur communication avec les usagers (Al-Daihani et Abrahams, 2016). Le développement de cette étude s’articule autour de deux questionnements essentiels ; à savoir, « de quoi parlent les bibliothèques municipales françaises sur Twitter ? » et « comment le disent-elles ? ». L’objectif est de parvenir à dégager la façon dont le discours des bibliothèques à l’intention des usagers s’organise et se structure sur Twitter.
Nous proposons ici de présenter, non pas les résultats de cette recherche2, mais la méthodologie qui a été la nôtre pour répondre à ces questionnements. D’un point de vue opératoire, notre méthodologie se traduit, dans un premier temps, par une typologisation manuelle des tweets publiés par un panel de bibliothèques municipales françaises qui est complétée, dans un second temps, par une analyse des données textuelles des discours produits dans ces tweets – grâce aux logiciels Tropes et IRaMuTeQ. Cette dernière étape a notamment fait l’objet d’une représentation visuelle sous la forme de graphes pour appuyer et faciliter notre interprétation des résultats obtenus – grâce au logiciel Gephi. Par cette mise en exergue graphique des structures et des contenus discursifs des tweets étudiés, ce procédé s’est effectivement révélé pertinent pour répondre à nos objectifs.
1. Matériel et méthodes
1.1. Terrain
La recherche dont nous présentons ici la méthodologie s’intéresse à l’usage que font les bibliothèques des réseaux sociaux numériques et plus particulièrement à leur production de contenus sur ceux-ci ; en d’autres termes, leur discours. À cette fin, le terrain de recherche retenu est Twitter 3 auquel les bibliothèques ont souvent recours pour répondre à de multiples enjeux et besoins communicationnels et promotionnels (Al-Daihani et Abrahams, 2016 ; Del Bosquet et al., 2012 ; Gunton et Davis, 2012 ; Milestein, 2009 ; Shulman et al., 2015). D’ailleurs, plusieurs chercheurs semblent s’accorder pour dire que les bibliothèques devraient utiliser Twitter pour interagir plus avec leurs usagers4 – et non pas seulement l’utiliser pour diffuser de l’information – afin de tirer le meilleur bénéfice de cette plateforme (Cole, 2009 ; Cuddy et al., 2010 ; Del Bosque et al., 2012 ; Dickson et Holley, 2010 ; Gaillard, 2015 ; Gunton et Davis, 2012 ; Milstein, 2009 ; Sewell, 2013).
« L’interaction entraîne l’interaction, et plus l’on répond, commente, met en favori, retweete, plus on peut obtenir en retour du contact, de l’engagement, des nouveaux followers et de l’intérêt pour l’institution, ses collections et ses services. » (Gaillard, 2015).
Une telle entreprise d’étude du discours des bibliothèques nécessite la constitution préalable pour analyse d’un corpus des tweets 5 des profils en question. Pour constituer ce dernier nous avons décidé de restreindre notre sélection aux profils de bibliothèques (ou médiathèques)6 qui remplissent les critères suivants : (1) la bibliothèque est française ; (2) la bibliothèque est municipale ; (3) la bibliothèque a un profil Twitter qui lui est propre ; (4) la bibliothèque a un profil Twitter actif depuis au moins un an au 30 juin 2020 ; (5) la bibliothèque a un profil Twitter qui a été actif en 2020 avant le 16 mars 2020. Nous avons finalement sélectionné aléatoirement les profils Twitter de 13 bibliothèques qui répondent à ces exigences (tableau 1).
Tableau 1. Informations sur les profils Twitter des bibliothèques retenues
| Profils Twitter | Dénomination | Commune (code département) |
| @BibBeaune | Gaspard Monge | Beaune (21) |
| @BibHavel | Václav Havel | Paris (75) |
| @biblideols | Eugène Hubert | Déols (36) |
| @bibliolocmine | - | Locminé (56) |
| @BibMolleges | - | Mollégès (13) |
| @bibvaugirard | Vaugirard | Paris (75) |
| @Italiebib | Italie | Paris (75) |
| @LaMejanes | La Méjanes | Aix-en-Provence (13) |
| @media_hyeres | Saint-John Perse | Hyères (83) |
| @mediateyran | - | Teyran (34) |
| @mediatheque_dz | Georges-Perros | Douarnenez (29) |
| @MediathequeC | Isidore Rollande | Châteaurenard (13) |
| @MMSenlis | - | Senlis (60) |
1.2. Échantillonnage
Cette sélection une fois faite, nous avons extrait, le 30 juin 2020, les publications des profils Twitter précédemment cités7 – grâce à l’extension Twlets (navigateur Google Chrome) qui permet d’exporter ces données sous la forme d’un tableur. Précisons que Twitter n’autorise l’extraction que de 3200 publicationspar profil. Twlets impose donc une restriction d’extraction à hauteur de cette autorisation ; il nous a donc été impossible de récolter la totalité des publicationsdes profils @BibHavel (4226 au 30 juin 2020) et @media_hyeres (4772 au 30 juin 2020)8. Nous avons extrait 15 584 publications de cette manière (tous profils confondus) ; le tableau 2 précise le nombre de publicationsrécoltées pour chacun des profils étudiés (colonne « Extractions »). Nous avons écarté trois types de publicationsde cette première extraction. Les publicationspostées pendant la période de confinement et de post-confinement due à la pandémie de Covid-19 ont été écartées en premier car nous souhaitions étudier des contenus produits en temps « normal » (avant le 16 mars 2020), les publications faites pendant cette période pouvant certainement répondre à des logiques inhabituelles. Les retweets 9 ont ensuite été écartés car ils ne constituent pas une publication originale. Enfin, nous avons écarté les commentaires mis en réponse à d’autres publications. Garder ces différentes publications aurait alors constitué un biais évident dans nos analyses et les conclusions qui en auraient découlé. Le corpus ainsi constitué est composé de 8991 tweets (tableau 2, colonne « Corpus »).
C’est finalement au sein de ce corpus que nous avons sélectionné des échantillons (pour un total de 2632 tweets [tableau 2, colonne « Échantillons »]) afin de mener à bien nos analyses et notre recherche. Analyser un échantillon a ceci d’intéressant que cela permet de produire des résultats à partir d’effectifs moindres. Il faut toutefois, pour que ces résultats soient statistiquement significatifs, que l’échantillon analysé comptabilise un nombre suffisant d’éléments pour être représentatif – de plus, l’échantillon doit être prélevé aléatoirement au sein de la population étudiée. Calculer la taille idéale minimale d’un tel échantillon à partir d’une population dont la taille est connue se fait selon la formule suivante :
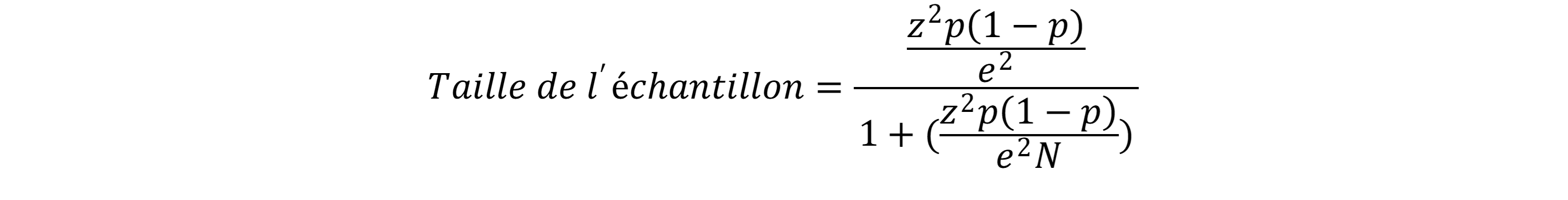
Tableau 2. Nombre de publications par extraction, corpus et échantillon des profils étudiés (30 juin 2020)
| Profils Twitter | Extractions | Corpus | Échantillons | Rapport corpus/extraction |
| @BibBeaune | 2169 | 1185 | 291 | 0,55 |
| @BibHavel | 3197 | 1706 | 314 | 0,53 |
| @biblideols | 665 | 600 | 235 | 0,9 |
| @bibliolocmine | 867 | 790 | 259 | 0,91 |
| @BibMolleges | 80 | 77 | 65 | 0,96 |
| @bibvaugirard | 2531 | 1411 | 303 | 0,56 |
| @Italiebib | 638 | 84 | 70 | 0,13 |
| @LaMejanes | 152 | 114 | 89 | 0,75 |
| @media_hyeres | 3242 | 1603 | 311 | 0,49 |
| @mediateyran | 741 | 646 | 242 | 0,87 |
| @mediatheque_dz | 226 | 204 | 134 | 0,9 |
| @MediathequeC | 444 | 385 | 193 | 0,87 |
| @MMSenlis | 264 | 186 | 126 | 0,7 |
| Total | 15 584 | 8991 | 2632 |
1.3. Typologie
Au-delà de l’intérêt heuristique, réaliser une typologie du discours des bibliothèques aiderait ces dernières à mieux déterminer quelles sont les catégories de publications les plus efficaces en termes de portée et d’engagement de l’auditoire. À travers l’analyse de ces publications discriminées, les bibliothèques pourraient ainsi être en mesure d’optimiser non seulement leur communication, mais aussi leurs services, leurs programmations, etc.
Nous avons donc catégorisé manuellement chacun des tweets qui constituent nos échantillons. D’autres chercheurs, comme Audouard et al. (2018) ou Stvilia et Gibradze (2014, 2017), ont déjà proposé des typologies de tweets de bibliothèques. Parce qu’elle nous semble plus détaillée et parce qu’elle a été élaborée sur la base d’un échantillon bien plus large, nous avons retenu pour socle de référence la typologie de Stvilia et Gibradze (2014, 2017), et ce, sans écarter la possibilité d’avoir à créer des catégories ad hoc si cela s’avérait nécessaire ; la typologie de référence s’étant toutefois montrée suffisante, cette éventualité ne s’est pas présentée. Cette typologie avait été structurée sur la base de l’analyse des tweets publiés par les bibliothèques universitaires de six universités publiques américaines membres de l’Association des universités américaines (Association of American Universities [AAU]). Elle s’articule autour de neuf types de tweets ; à savoir, « événement » (event), « ressource » (resource), « développement de la communauté » (community building), « état du service » (operations update), « soutien aux études » (study support), « personnel » (staff), « enquête » (survey), « club » (club) et « question et réponse » (Q&A) (tableau 3).
Tableau 3. Typologie des tweets de bibliothèques universitaires selon Stvilia et Gibradze (2014, 2017)
| Catégories | Définitions |
| Événement (event) | Cette catégorie inclut les tweets qui concernent les événements qui sont généralement hébergés par les bibliothèques (ateliers, animations, projections, inaugurations, expositions, conférences, etc.). |
| Ressource (resource) | Cette catégorie inclut les tweets qui concernent les ressources mises à disposition par les bibliothèques (catalogue, ressources numériques, abonnements, blog, etc.). Cette catégorie inclut aussi les ressources trouvées sur le Web que les bibliothèques souhaitent partager. |
| Développement de la communauté (community building) | Cette catégorie inclut les tweets qui font la promotion des bibliothèques comme lieux où l’on peut recevoir de l’aide pour ses recherches, où l’on peut faire une sortie, se réunir, se divertir, etc. Cette catégorie inclut aussi les encouragements et les félicitations envers les usagers (pour, par exemple, la réussite aux examens) ou envers les bibliothèques elles-mêmes (pour, par exemple, l’obtention d’un label). |
| État du service (operations update) | Cette catégorie inclut les tweets qui font le point sur les mises à jour du service des bibliothèques (heures et jours d’ouverture, fermetures exceptionnelles, maintenances, problèmes techniques, etc.). Cette catégorie concerne aussi les aménagements des différents espaces. |
| Soutien aux études (study support) | Cette catégorie inclut les tweets qui font la promotion des bibliothèques comme lieux d’étude et qui fournissent de nombreux services d’aide et de soutien aux études. |
| Personnel (staff) | Cette catégorie inclut les tweets qui présentent les membres du personnel des bibliothèques. Cette catégorie présente aussi les derniers recrutements et/ou les offres d’emplois. |
| Enquête (survey) | Cette catégorie inclut les tweets qui diffusent des enquêtes auprès des communautés d’usagers. Cette catégorie inclut aussi les recrutements de volontaires pour tester de nouveaux services. |
| Club (club) | Cette catégorie inclut les tweets qui présentent les groupes et les clubs hébergés par les bibliothèques (groupes de jeux, clubs de lecture, etc.). |
| Question et réponse (Q&A) | Cette catégorie inclut les tweets qui répondent aux questions habituelles sur le service et le fonctionnement des bibliothèques (horaires d’ouverture et de fermeture, modalités d’emprunt, tarifs, etc.). |
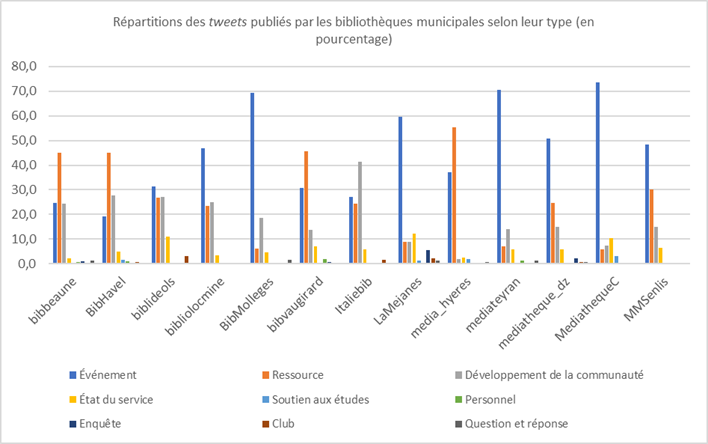
Par exemple, la typologisation des tweets des bibliothèques nous a permis dans un premier temps de dégager la répartition globale (figure 1) ou détaillée (figure 2) des publications des organisations observées. On constate notamment, sur la répartition globale, que la communication des bibliothèques sur Twitter repose sur trois piliers ; à savoir, les tweets « événement » (41,6 %), les tweets « ressource » (31,7 %) et les tweets « développement de la communauté » (17,9 %). À eux trois, ces types de tweets occupent 91,2 % du volume total des contenus directement publiés par les bibliothèques sur Twitter10. Quant à la répartition détaillée, on peut y apprécier les variations qui existent d’une bibliothèque à une autre. On voit notamment que, sur les treize profils étudiés, huit profils enregistrent une publication majoritaire de tweets « événement » (@biblideols, @bibliolocmine, @BibMolleges, @LaMejanes, @mediateyran, @mediatheque_dz, @MediathequeC, @MMSenlis), quatre autres profils enregistrent une publication majoritaire de tweets « ressource » (@bibbeaune, @BibHavel, @bibvaugirard, @media_hyeres) et, enfin, un dernier profil enregistre une publication majoritaire de tweets « développement de la communauté » (@Italiebib).
Figure 1. Répartition moyenne des tweets publiés par les bibliothèques municipales selon leur type (en pourcentage)
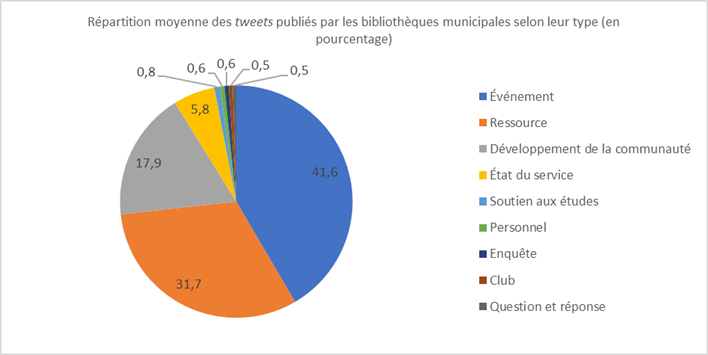
Figure 2. Répartitions des tweets publiés par les bibliothèques municipales selon leur type (en pourcentage)
1.4. Analyse de données textuelles
Nous avons souhaité accompagner la typologisation des tweets par une analyse de son contenu textuel11. Cette méthode est de plus en plus utilisée dans les recherches sur les bibliothèques (Al-Daihani et Abrahams, 2016).
Au-delà d’un cadre de recherche académique, les données textuelles extraites des médias sociaux sont souvent utilisées – de façon plus ou moins sophistiquée – par les organisations pour, d’une part, analyser les discours produits par les usagers et, d’autre part, appuyer la prise de décision stratégique (Abrahams et al., 2015). Les bibliothèques pourraient tirer avantage de cette méthode (Zhang et Gu, 2011), que ce soit en analysant les discours produits par leurs usagers, par d’autres bibliothèques ou par elles-mêmes. En effet, les renseignements et les conclusions issus de telles analyses peuvent être exploitables comme autant d’aides à la prise de décision stratégique, que ce soit pour optimiser une communication en ligne, une offre de services ou autre.
Pour analyser les données textuelles produites, nous utilisons les logiciels Tropes et IRaMuTeQ. Si Tropes peut sembler relativement primaire comme outil d’analyse sémantique, c’est justement sa simplicité d’utilisation qui pourrait faire sa force dans le cadre d’un usage professionnel par des bibliothécaires qui ne seraient pas formés à ce genre de méthodologies.
Tropes et IRaMuTeQ réalisent des analyses qui reposent sur des lemmes et les éventuelles connexions entre ceux-ci. Toutefois, il existe quelques subtilités de fonctionnement entre ces deux logiciels qu’il nous semble important de relever car elles peuvent être source de légères variations dans les données et résultats présentés (tableaux 4 et 5). Tropes réalise ses analyses sur les « Références » présentes dans un texte ainsi que les éventuelles « Relations » entre celles-ci. « Les Références représentent le contexte. Elles regroupent, dans des classes d'équivalents, les principaux substantifs du texte que vous analysez. » et « Les Relations indiquent quelles Références sont fréquemment reliées (c'est-à-dire rencontrées à l'intérieur d'une même proposition), dans le texte analysé. » (Molette et Landré, 2018). IRaMuTeQ,quant à lui, réalise ses analyses sur des « formes » présentes dans un texte ainsi que les éventuelles « cooccurrences » entre celles-ci. « Le logiciel fait une lemmatisation […] à l’aide de ses dictionnaires et peut ainsi regrouper les formes au singulier et au pluriel sous une même forme, les verbes conjuguées sous la forme infinitive. » (Baril et Garnier, 2015, p. 8). Une autre différence en termes de traitement des corpus est à noter, IRaMuTeQ considère les verbes dans son analyse et les restitue dans son fichier exportable pour la mise en graphe sous Gephi alors que Tropes les traite aussi mais ne les inclut pas dans son fichier exportable pour la même destination. Cette différence de traitement est intéressante dans le cadre d’une lecture croisée et complémentaire des résultats.
Il convient également d’exposer les limites de ces logiciels. Les résultats des analyses réalisées par Tropes ou IRaMuTeQ sont plus significatifs à mesure que les corpus analysés se densifient. Or, dans le cas des tweets, ceux-cisont limités à un maximum de 280 caractères, ce qui peut être un biais. C’est pourquoi nous réalisons nos traitements sur des compilations de tweets que nous pouvons discriminer en fonction de la typologie et/ou du profil.
Avec les résultats bruts obtenus, nous pouvons dans un premier temps procéder à une lecture quantitative de ceux-ci. Tous les lemmes et toutes les connexions sont classés selon leur nombre d’occurrences. En d’autres termes, nous pouvons déjà dégager de ces données les lemmes les plus employés dans les tweets et leurs associations les plus marquées, ce qui revient en quelques sortes à extraire les caractéristiques textuelles diagnostiques des tweets de notre corpus, et ce, selon leur type. Dans un deuxième temps, nous pouvons ensuite faire une lecture plus qualitative de ces résultats. L’analyse sémantique discriminée des corpus permet ainsi de révéler les cohérences entre le sens dominant dégagé du contenu textuel des tweets analysés et les thématiques induites par la typologie qui leur est associée. Pour des raisons pratiques de lecture, les résultats présentés à titre d’exemple ne présentent que les dix références/formes et les dix relations/cooccurrences les plus importantes – selon différentes variables – pour les tweets « événement » (tableaux 4 et 5).
Par exemple, la lecture croisée des analyses textuelles des tweets « événement » nous révèle une composition qui s’articule principalement autour de constructions ayant pour base les références « samedi », « exposition », « médiathèque » ou « bibliothèque », « atelier », « lecture », « découverte » ou « découvrir » et « livre » (tableaux 4 et 5)12. Cette base discursive est fréquemment complétée et précisée par d’autres indications. Ces indications sont notamment spatiales et sont induites par l’utilisation des références « pays » qui agrègent en une catégorie des noms de pays et de villes (tableau 4). Ces derniers peuvent renvoyer au lieu de l’événement ou bien à son thème (comme une exposition sur le Japon). Ces indications sont également temporelles puisqu’on observe une utilisation marquée des références « mois » qui regroupent les différents mois de l’année (tableau 4). Il s’agit donc d’un complément de date. Au vu de ces résultats, nous pouvons donc interpréter que la majorité des tweets « événement » font la promotion d’expositions, d’ateliers et de lectures publiques. Ces événements se produisent principalement au sein des bibliothèques, plutôt le samedi, et leur entrée est libre et gratuite (cf. relations « entrée > libre », « libre > gratuité » et « entrée > gratuité », et cooccurrences « entrée/libre », « samedi/gratuit » et « gratuit/libre »). Plusieurs événements, notamment les lectures, s’adressent aux enfants (cf. relations « enfants > années » et « livre > petit »).
Tableau 4. Exemple des références et relations des tweets « événement » (Tropes)
| Tweets « événement » | |
| Références par fréquence (nombre d’occurrences) | mois* (483), pays* (313), samedi (223), médiathèque (167), littérature* (139), exposition (125), lecture* (111), années (107), atelier (103), bibliothèque (101) |
| Références par nœuds voisins (nombre de liens uniques connectés) | samedi (83), exposition (66), médiathèque (59), atelier (55), lecture* (54), bibliothèque (48), découverte* (38), années (36), livre (36), mercredi (34) |
| Références par degrés (nombre de liens connectés) | samedi (115), exposition (77), médiathèque (77), lecture* (66), atelier (64), bibliothèque (61), découverte* (44), années (42), livre (42), concours* (38), mercredi (38) |
| Relations par poids (nombre d’occurrences) | entrée > libre† (57), libre > gratuité† (29), samedi > mars (26), enfants > années (24), livre > petit† (23), samedi > décembre (22), atelier > écriture (21), bibliothèque > bouches-du-rhône (20), samedi > janvier (20), samedi > juin (20), samedi > octobre (20), semaine > mardi (19), semaine > samedi (19), entrée > gratuité† (18), rendez-vous > samedi (18), gratuité > inscription† (18), mardi > samedi (18), samedi > février (18) |
Tableau 5. Exemple des références et relations des tweets « événement » (IRaMuTeQ)
| Tweets « événement » | |
| Formes par fréquence (nombre d’occurrences) | samedi (204), médiathèque (135), venir (98), atelier (86), bibliothèque (81), exposition (81) , lecture (77), gratuit (73), partir (69), livre (66), libre (66) |
| Formes par degrés (nombre de liens connectés) | samedi (115), bibliothèque (38), médiathèque (32), venir (30), découvrir (19), atelier (16), gratuit (15), exposition (14), livre (12), douarnenez (12), lecture (12) |
| Cooccurrences par poids | samedi/médiathèque (10), entrée/libre (9.8), samedi/gratuit (5.5), samedi/15h30 (5.3), gratuit/libre (4.9), samedi/atelier (4.3), venir/médiathèque (4.3), samedi/partir (4.3), 17h/samedi (3.9), place/rester (3.7), samedi/lecture (3.7), samedi/janvier (3.7) |
1.5. Analyse de réseaux
Enfin, pour faciliter la lecture des données précédemment récoltées, nous avons souhaité représenter graphiquement ces dernières, plus particulièrement sous la forme de graphes, puisque la présence de relations et de cooccurrences entre des lemmes le permettait. Cette mise en forme visible nous a paru nécessaire pour optimiser l’interprétation des données produites car, comme le disait Bertin :
« Les données ne fournissent pas l’information nécessaire à la prise de décision. Ce qu’il est nécessaire de voir ce sont les relations que l’ensemble des données construit. […] la graphique peut faire découvrir les relations d’ensemble. C’est son but. […] c’est un système de signes, rigoureux et simple, que chacun peut apprendre à utiliser et qui permet de mieux comprendre. Il permet donc de mieux décider. » (Bertin, 2017, p. 1).
Les fichiers exportés à partir de Tropes et d’IRaMuTeQ permettent chacun de créer un type de graphes différent (grâce au logiciel Gephi qui est spécialisé dans l’analyse et la visualisation de réseaux). Les nœuds (ou sommets) y représentent les références/formes et les liens (ou arrêtes) y représentent les relations/cooccurrences. Chacun de ces graphes a été décliné sous deux formes ; à savoir, une forme qui met évidence la fréquence des références/formes (taille des nœuds proportionnelle au nombre d’occurrences des références/formes qu’ils représentent) et une forme qui met en évidence le degré de connexion des références/formes entre elles (taille des sommets proportionnelle au nombre de liens qui les connectent avec d’autres sommets). L’épaisseur des liens est proportionnelle aux cooccurrences des sommets qu’ils connectent. Pour des raisons pratiques de lecture, les graphes proposés à titre d’exemple sont des versions simplifiées avec un nombre réduit de sommets et d’arrêtes (figures 3 et 4).
Les fichiers GEXF13 exportés de Tropes permettent la création de graphes orientés qui mettent en réseau toutes les références et les relations extraites des corpus étudiés (figure 3). Précisons que dans un graphe orienté, les cooccurrences peuvent être bilatérales. Un des avantages de ce type de graphes est de fournir un réseau complet de toutes les références et relations qui composent un corpus. Toutefois, leur lecture se complexifie à mesure qu’ils se densifient. L’intérêt d’utiliser Tropes pour produire ce genre de graphes est que ce logiciel précise le domaine conceptuel auquel les références appartiennent. Dans la figure 3, les références appartenant à un même domaine conceptuel sont représentées par des sommets de même couleur.
Figure 3. Exemples de graphes orientés des références et des relations des tweets « événement »
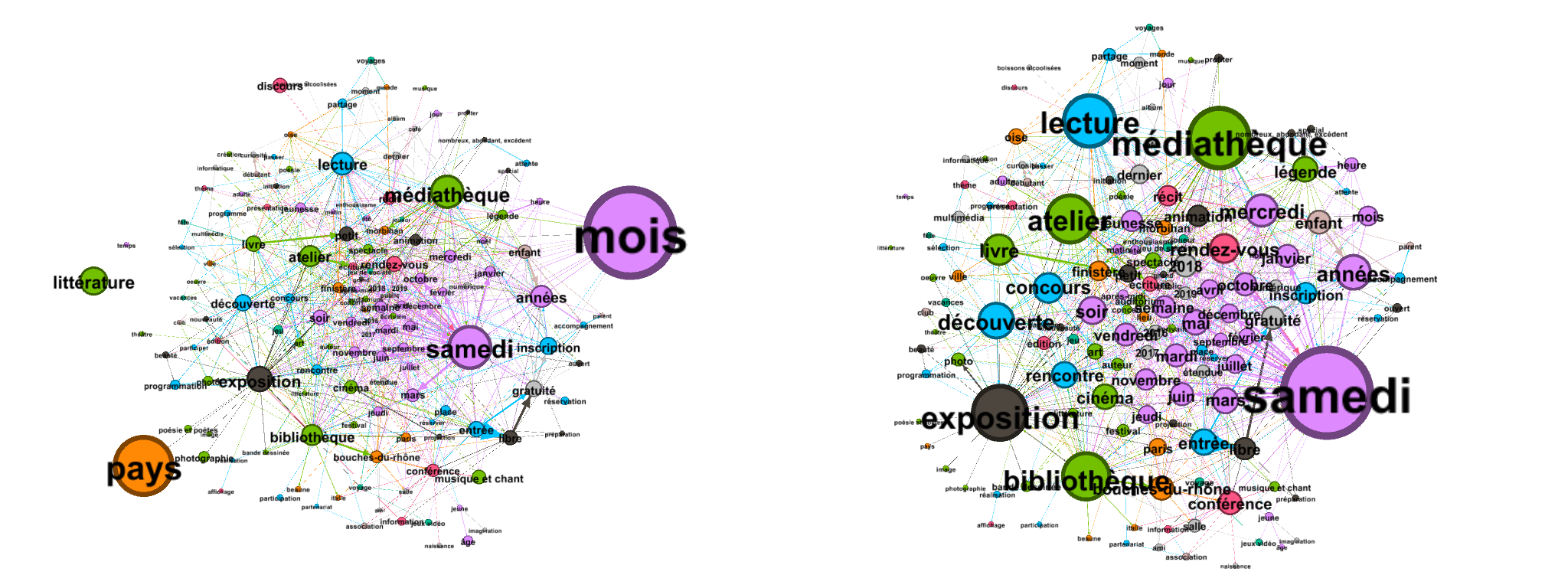
Le graphe de gauche met l’emphase sur la fréquence des références et celui de droite sur leur degré de connexion
Les fichiers GraphML14 exportés d’IRaMuTeQ permettent la création de graphes non- orientés qui traduisent graphiquement une analyse des similitudes sous la forme d’un « arbre maximum » de toutes les formes et cooccurrences extraites des corpus étudiés (figure 4).
« L’objectif de l’ADS est d’étudier la proximité et les relations entre les éléments d’un ensemble, sous forme d’arbres maximum : le nombre de liens entre deux items évoluant "comme le carré du nombre de sommets" (Flament et Rouquette, 2003, p. 88), l’ADS cherche à réduire le nombre de ces liens pour aboutir à "un graphe connexe et sans cycle" (Degenne et Vergès, 1973, p. 473). » (Marchand et Ratinaud, 2012, p. 688).
Un des avantages de ce type de graphes est de simplifier la lecture des données récoltées tout en mettant en avant les cooccurrences les plus fortes. Un autre de leurs avantages est de permettre la détection de communautés de lemmes. Ces communautés sont constituées de lemmes fortement cooccurrents ; les différentes communautés sont reliées entre elles par des liens plus faibles. Dans la figure 4, les lemmes au sein d’une communauté sont représentés par des sommets de même couleur.
Figure 4. Exemples d’arbres maximum des formes et des cooccurrences des tweets « événement »

Le graphe de gauche met l’emphase sur la fréquence des formes et celui de droite sur leur degré de connexion
Conclusion et perspectives
Dans cet article, nous avons présenté la méthodologie que nous appliquons dans nos recherches actuelles sur l’usage des réseaux sociaux numériques par les bibliothèques municipales françaises. À travers cette présentation, nous avons également souhaité mettre en avant les bénéfices que pourraient tirer les bibliothèques des analyses de données textuelles. En effet, les renseignements et les conclusions issus de telles analyses peuvent être exploitables comme autant d’aides à la prise de décision stratégique, que ce soit pour optimiser une communication en ligne, une offre de services ou autre. Plus généralement, Audouard et al. (2018) et Sandhu (2015) insistent sur l’importance et les enjeux, pour les bibliothèques, d’exploiter, pour les premiers, les données métriques fournies par les réseaux sociaux numériques et, pour le second, de se former à l’extraction de données et aux outils de Big Data. Par exemple, Shulman et al. (2015) ont analysé le réseau social Twitter de deux bibliothèques universitaires américaines pour y identifier les usagers les plus influents afin de les « recruter » pour améliorer la diffusion de l’information auprès du reste des usagers.
Pourtant, si chercheurs, bibliothèques et autres praticiens des sciences de l’information et de la communication ont proposé plusieurs modèles et conseils pour répondre à cet enjeu dans un cadre « traditionnel » (hors ligne), peu de recherches ont en revanche cherché à y répondre dans le cadre des réseaux sociaux numériques. Il y a donc un réel besoin, pour les bibliothèques, en termes de modèles aussi bien théoriques que pratiques et opérationnels pour diffuser une information efficace sur ces plateformes (Stvilia et Gibradze, 2014). C’est pourquoi, partant de ce principe, et au-delà de l’intérêt heuristique de notre recherche, nous souhaitons aussi dépasser le cadre académique pour proposer à terme une méthodologie opérationnelle que les bibliothèques pourraient utiliser afin d’optimiser leur communication en ligne.
À cette fin, nous envisageons à terme de mener une recherche- action en bibliothèque où nous proposerions, entre autres, des formations à l’analyse de données extraites des réseaux sociaux numériques, et ce, notamment sur la base de nos travaux actuels et à venir.